

마모에 데이터쪽 일하시는 분들도 꽤 계신것 같아서 함 올려봐요.
인스타 창업자/CEO였던 케빈 시스트롬이 자기가 Python으로 모델 짠거 Github에 올렸네요. 최고경영자가 아직도 이렇게 코딩을 깔끔하게 할수 있다니! 감탄을 금치 못하며 여기 한번 올려봅니다.
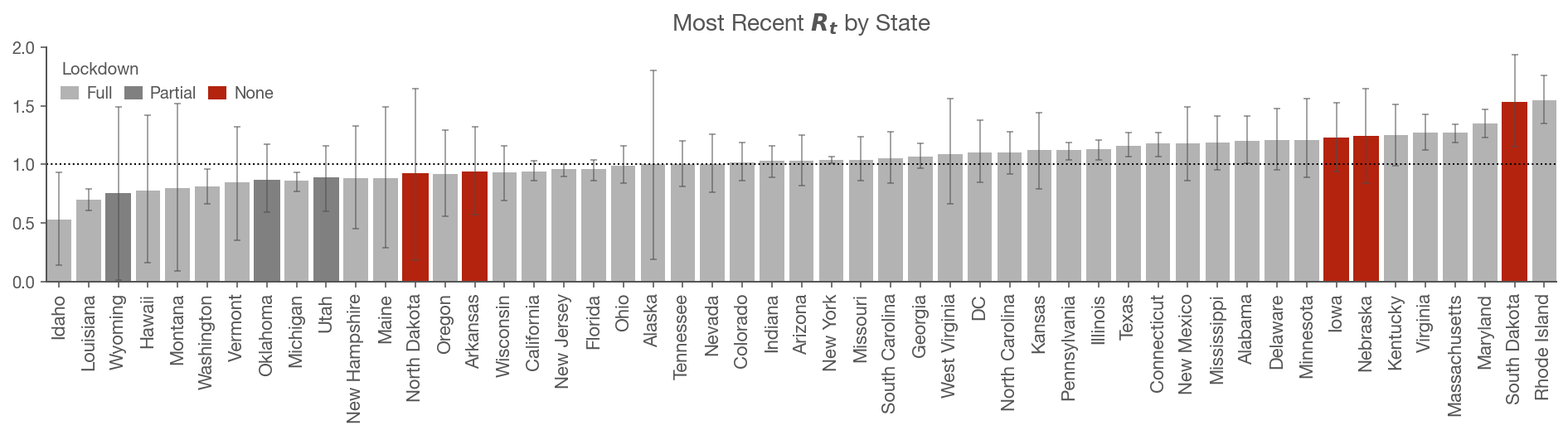
아래는 주별 전파율을 보여주는 모델 결과예요. (매일 업데이트 되는듯) @재마이 님이 걱정하셨던 메릴랜드가 현재 3위네요.
코드가 궁금하신 분들은 여기!
https://nbviewer.jupyter.org/github/k-sys/covid-19/blob/master/Realtime%20R0.ipynb
1등. 대단한데요. 그나저나 결과가 의미가 있는 건가요?
제 코드랑 다를 게 없어 보여요(쿨럭)
각 주별로 Rt 를 real-time으로 한눈에 보여준다는게 큰 의미인것 같아요. (이런 분석은 아직 못봤거든요)
근데 코딩고수이신듯요 ^^
그렇게 되고 싶은 염원을 적어 본 것입니다. real-time 으로 보여준다는 것이 의미가 있다는 것이었군요. 좀 읽다가 말았는데 사실 문제를 해석하고 시뮬레이션을 셋업하는것이 더 큰 부분이지 않을까 생각됩니다. 생각을 구현할 사람들은 좀 되는데 문제 해결을 위한 바른 접근을 하기는 쉽지 않은 법이니까요. 대단하신 분이시네요. 주말이라서 기술 문서를 길게 읽고 싶지 않네요.
그런데 poisson distribution 이 잘 맞을까요?
아마도 기존이 있는 distribution 중에는 가장 잘 맞지 않을까 싶습니다. 보통 count 혹은 rate은 poisson 을 가정하고 모델링합니다. 물론 포아송의 단점을 보완한 모델들도 있으나 이런 상황에서는 기본적인 방법부터 시작하는게 맞다고 생각됩니다.
오 감사합나다. 엄청난 고수란 이야긴 듣긴 했는데 역시 대단한 분이시네요.사우스 다코다 함 눈겨워 봐야겠네요~
텀이 적긴하지만 MA RI 그리고 여긴 없지만 PA 의 예를 보면 세컨드 웨이브는 벌써 온 듯 합니다.
MD에 사는데 오늘 2주만에 장보러 나갓더니 2주전이랑은 분위기가 확실히 달라서 놀랏습니다.
사람이 평소 주말처럼 많았구요. 2주전에는 다들 저처럼 2주치 식량 사느라 카트에 모두 물건이 가득햇는데, 오늘은 카트 가득 식료품 사는 분들이 전체에 20프로 정도밖엔 되지 않더군요. 그말은 아마 다들 예전처럼 일주일에 한두번씩 장보러 나오겟다는거 같던데. 뉴스에 뉴욕 인근에 확진자가 증가세가 안정권에 들엇다고 사람들이 안심을 하기 시작한건지. 아니면 한달 가까이 되면서 사람들이 무뎌진건지 모르겟지만 걱정이 많이 되네요. 나혼자만 잘한다고 지나갈수 잇는 일이 아닌데요 ㅠㅠ
베이지언 미만은...
제가 있는 쪽에서는 poisson arrival을 보통은 너무 optimistic한 걸로 보는데 이쪽 도메인에서는 적절한 가정인가요. 모델링에 대해서 커멘트 해주실 수 있는 분 계실까요.
모든 코드를 공개할수 있는 자신감이 멋지네요. 남의 일을 평가하기는 쉬워도 무언가를 내놓고 평가의 대상이 되는건 좀처럼 쉬운일은 아닌텐데요. 특히 요즘과 같은 시기의 이런 민감한 주제는 더더욱 ㅎㅎ
멋지네요. 나중에 코드좀 읽어봐야겠네요.
다른거 다 떠나서, jupyter notebook좋은거같아요... 석사때부터 matlab을 써오다보니 spyder만 썼었는데, 이렇게 문서화할 필요가 종종있는데... 막상 넘어가기가 귀찮기도하고 어려워서 미루는데 얼렁 해봐야겠네여 ㅠ
https://colab.research.google.com/ 추천합니다. 로컬에 아무 세팅도 필요 없으시구요, 주피터 노트북 여기서 작성 가능합니다.
(원 논문을 대충 읽어보긴 했지만 제대로 파악한건지 약간 자신이 없는데) R value를 추정하려는 모델 자체는 말이 됩니다만 보고된 케이스의 숫자만을 일차적인 정보로 R값을 추정하는 건, 확진자를 exhaustive하게 잡아내거나 , 최소한 실제 확진자 수 중에서 컨펌되는 확진자 수의 비율이 day-to-day로 일정하다는 전제가 있어야 가능할텐데요. 검사역량이 saturate된 상황에서는 확진자 숫자라는게 그냥 검사역량에 비례해서 나오게 되는 값이지 실제 환자수의 몇 %인지를 추정할 수가 없죠... 현재 (확진률이 30% 이렇게 나오는) 미국 데이터로는 그냥 garbage in garbage out 이상의 결과를 주지 못 할 것 같다는게 저의 좀 성급한 결론입니다.
저도 마지막 부분에 동의합니다. Data quality를 확인할 수 없으니 그점이 가장 큰 한계죠. 하지만 주어진 데이터가 쓸만하고 어느정도는 믿을 수 있다고 가정하지 않으면 결국 아무것도 못하는 것 같아요. 어렵네요.
edta450 님의 견해에 동의합니다. 다만, Rt의 계산 전날들의 cumulative product 로 계산되어 distribution을 inform 하기 때문에 매일 검사역량이 증가한다는 가정하에 시간이 지나면 지날 수 록 Rt에 대한 uncertainty가 매우 개선되는 점이 있습니다 (실제로 날짜별 개별 state의 Rt를 plot 해 놓은 그래프를 보시면 나와 있습니다). 그래서 제 생각엔 garbage-in garbage-out 수준은 아닌 것 같습니다만 이 부분에서 검사역량과 mortality의 연계한 under-reporting을 고려해 봐야 하지 않을까 생각되 듭니다 (이와 관련된 pre-pub 논문을 본 적이 있는데 그 논문에서는 한국은 보고된 환자가 prevalent case의 88%라 나왔고 반면 미국을 포함한 대다수의 나라에서는 20%도 안 된다고 reporting 되어져 있었습니다).
이와 관련된 pre-pub 논문을 본 적이 있는데 그 논문에서는 한국은 보고된 환자가 prevalent case의 88%라 나왔고 반면 미국을 포함한 대다수의 나라에서는 20%도 안 된다고 reporting 되어져 있었습니다
>>> 저도 요게 핵심인것 같아요. 이 쪽으로 좋은 논문잇으면 링크 주세요.
https://cmmid.github.io/topics/covid19/severity/global_cfr_estimates.html
미국 12% 영국 4% 어쩔...
베이지역 산타클라라 카운티는 1/50 ~ 1/85 정도만 확진 된 것으로 추정되고 있습니다
저도 까막눈이 대충 읽어서 파악한 건데요. 참트루 베이지언이라면, k 확진자가 확진되엇을때, 실제 확진자가 r*k 일 확률을 구해야 하지 않나요?
@손님만석 님이 늘 강조하시는 거지만, 테스트 키트가 부족하면 데이타 자체가 unobserved가 더 많은 garbage in 이 된다고 봅니다.
그나저나 쥬피터 노트북 좋네요. Latex 쓰던 사람에게는 신세경이네요 ㅋ
선진문물은 얼른 배워야...
예, 동의합니다. 오늘도 제가 올렸는데 테스트수가 적거나 테스트를 많이 해도 확진율이 높은 (테스트가 부족하다는 해석가능) 주가 너무 많은 상태에서 이런 분석은 의미가 없지요. 50개주중에서 반은 이런 주일듯 합니다. 한국이 현재 사회적 격리를 하고 마스크 (그것도 KN95 마스크)를 거의 착용하고도 1500명/10만명을 테스트하고, 추적하고 해서 겨우 잡았는데 미국은 마스크도 적절하지 않고 (대부분 그냥 천마스크) 추적 하나도 안하고 병원들어 오는 중증환자만 겨우 테스트하고 있는 상태라 저런 분석은 시간 낭비입니다. 이런걸 정치적으로 이용할려고 하는게 아닌가 걱정 부터 듭니다. 인스타도 집에만 있으면 훨씬 줄것이므로(광고도 당연히 줄것이고) 그런가 하는 생각도 하게 되구요.
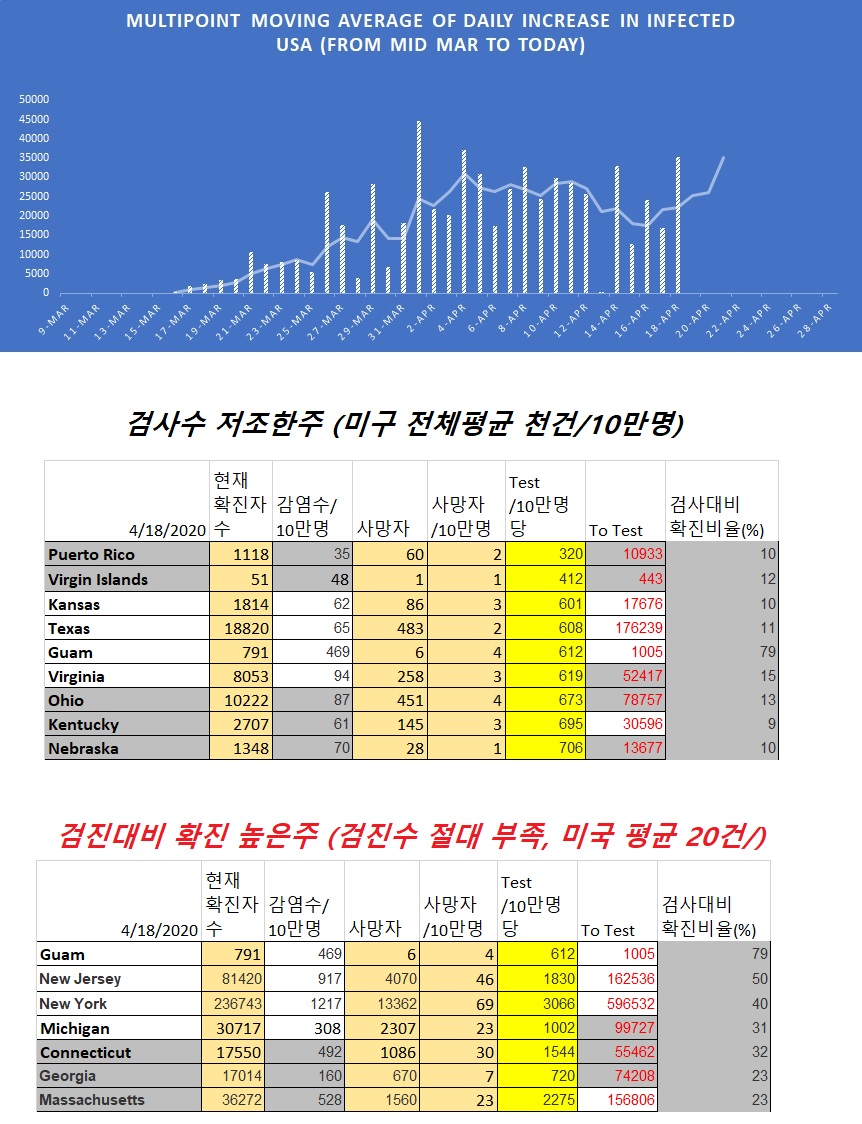
아니, 제가 볼땐 시간낭비 까지는 아니구요.
이론은 좋은데, 실제 예측력에 약점이 잇으니,
말씀하신대로, 검사대비 확진률 데이타를 이용해서 "숨겨진" 확진자 숫자를베이지언으로 예측하는 단계를 하나 더 집어 넣으면 손님만석 님이 기대하는 그런 예측모델이 가능할 것 같습니다.
멋있네요. 이런 시도들이 있어야 위에 마모분들이 이미 하신 것처럼 분석의 타당성/한계점도 논의되고 그래서 더 좋은 모델링 더 좋은 예측결과 더 좋은 시각화도 이루어진다고 생각합니다.
오 댓글에 좋은 얘기가 많이 나왔길래 갑자기 궁금해져서 저도 얹어서 물어볼게요.
gamma (=serial interval의 역수) 역시 꽤나 dispersion이 있는 그것도 -값도 드물지 않은 random variable이던데 이건 그냥 point estimate(=1/4)을 플러그인해서 R의 posterior를 구하는게 이 쪽(epidemiology)에서 일반적으로 수용되는 model calibration일까요?
확진자 kt 조건부라 해도 R과 gamma가 전혀 독립이 아닐거 같은데, 그럼 제아무리 믿을만한 kt가 쌓여나간들 R에 대한 추정은 사실 그냥 gamma와의 joint prior에 의존할 뿐 다른 데이터 없이 좁혀들어가는데 한계가 있을 거 같아보여서요.
가령 R이 낮아지는게 gamma이 작아지는 것(serial interval이길어지는 것)과 함께 나타나는데 gamma를 고정시키는 바람에 R을 더더 낮게 추정했다면.. 정책적으로는 이러나저러나 상관없는건가요?
지금 Lousiana 가 가장 안전하다는 소린가요? 좀 믿기가 어렵...
이게 보여주는게 누적이 아니라 현재시점의 전파율이라 그래요. 한바탕 쓸고 지나간 뒤에 현 시점에서의 상승곡선은 완만해진 상태라고 보시면 될듯해요.
역시 다방면의 대명사 밍키님 이시네요. ㅋㅋ 오하이오가 인구 숫자에 비해 굉장히 선방하고 있는거죠? 주뽕은 아닙니다 ㅋㅋ
케빈 이 친구 회사 그만두고 잉여력이 넘치네요. 저는 대학교 교양 통계가 마지막이어서 이해를 하려고 하니 좀 머리가 아프네요 ㅎㅎ 그래서 호재입니까?
댓글 [35]